Département Traitement Automatique des Langues (TAL)

Auteur : Pierre Mercuriali
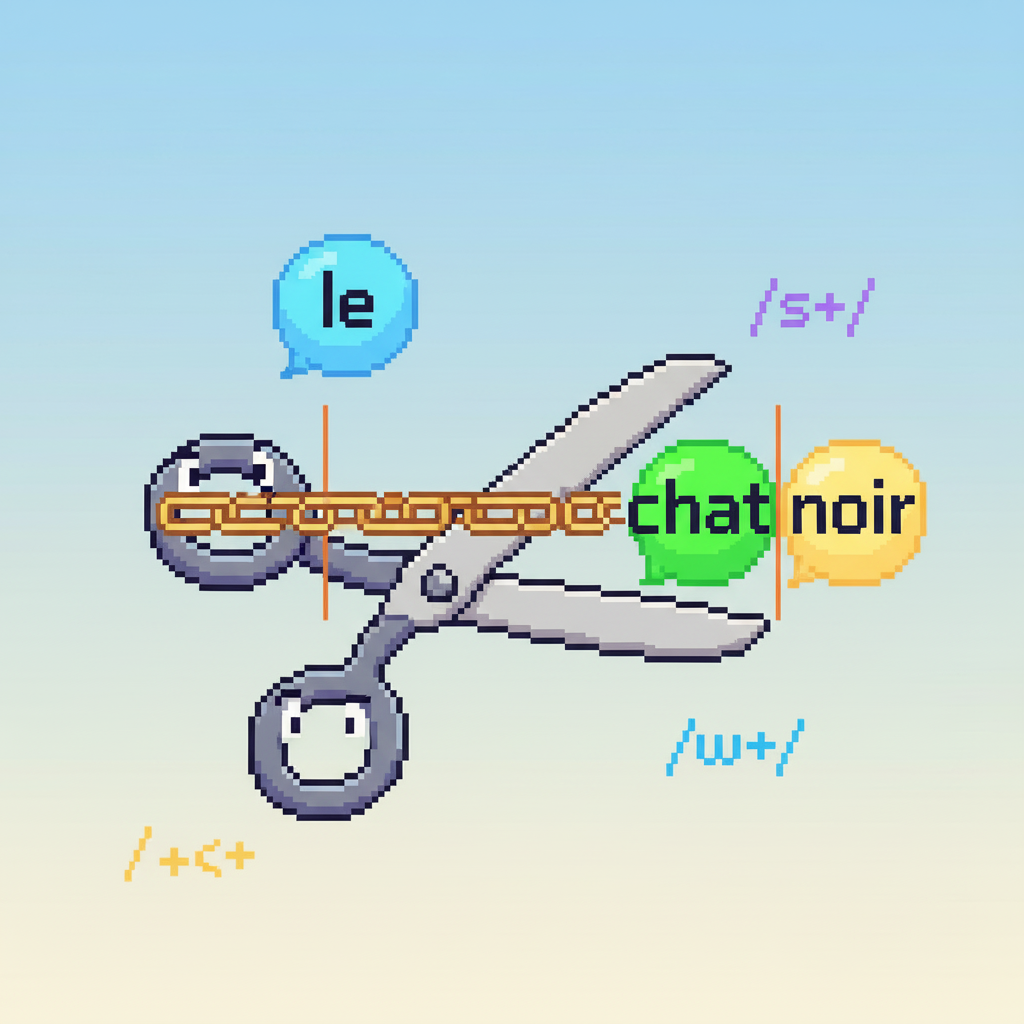
La tokenization est la conversion d'un texte (une grosse unité de langage) en unités plus petites (caractères, mots, etc.) en vue de leur traitement automatique. Les tokenizers de cette page fonctionnent à partir des règles suivantes :
’'.,;?!"()-«» \w+(?:'\w+)?|[^\w\s] Le but de cette page est de tester ces différentes règles, de les comparer, de voir où elles fonctionnent, et où elles ne fonctionnent pas.